
数百万冊におよぶ書籍の単語を、ビッグデータと捉えたら何が見えてくるのか? Google がスキャンした大量の書籍で使われている単語・フレーズの使用頻度を年ごとにプロットするシステム「グーグル・N グラム・ビューワー」。本書はこのビューワー自身の開発者によって、「カルチャロミクス」と名付けられた全く新しい人文学研究を紹介した一冊である。本稿では、この研究の背景となる「経済物理学周辺の最前線を、東京工業大学の高安 美佐子氏に解説いただいた。(HONZ編集部)

コンピュータを使った新しい文章の読み方
通常、文章の書き手は、どういう順番で話を展開すれば、読み手に内容を伝えられるかを考えながら言葉を一つひとつ選び、それらをつないでいく。そして読み手は、初めの単語から順番に読み解き、その内容を理解する。しかし、本書のテーマとなっているように、コンピュータを用いた分析技術を用いれば、人間が文章を理解する方法とはまったく異なる数理的な方法で文章を“読む(解析する)”ことができる。文章をその最小の構成要素である単語に分解し、現れた単語の数の変動や分布から定量的に文章の特徴を抽出する方法である。
解析対象の文章は、かつては個々の公式記録文書や小説や雑誌や新聞記事であった。それを本書著者の研究は、グーグル・ブックスのデータを利用して過去数世紀分の書籍、数百万冊を対象にできるようにし、それを一般の人でも利用可能なものにした画期的なものだ。だが、その研究成果であるグーグル・Nグラム・ビューワーは、残念ながら日本語には対応していない。
とはいえ、日本でも、インターネットや携帯端末の普及により、収集可能な文章が大きく広がった。インターネットを日常的に使う人の数は、現在、日本だけでも一億人を超え、ブログやSNSなどの利用者も数千万人のレベルになっている。これだけ多数の人が毎日利用しているので、ブログやSNSなどの書き込み記事を分析することでさまざまな興味深い情報を引き出すことができる環境が実現している。また、インターネット上では、新たに書き込まれたブログなどの記事を自動的に収集するシステムがさまざまな企業によって提供されており、日々、どのような言葉が使われているかを網羅的にリアルタイムに近い状態で観測することができる。
もちろん、このようにコンピュータを利用し、統計的な手法を用いて文章を解析して得た知見は、人間の脳が行っているような文章の理解とは異なるが、人間には読み取れないような発見、たとえば「ブームに見られる人間の集団行動の特徴」「言語が持つ普遍的な特徴」などが見えてくる。本書著者らの研究は、数年単位の時間スケールのものだが、その研究で見られるような人間の集合的な行動の特徴が、ネット上の書き込みの分析では、数週間・数日・数時間の時間スケールで観察できるのである。
言葉から見える、ブームに見られる人間の集団行動の特徴
従来、人々がどのようなことを考えているのかを知るためには、電話や街頭でアンケートを行うなど、手間とお金をかけて調査していた。しかし、インターネット上のブログ記事を活用すれば、人々の生活の様子などの膨大な記録を調べることが可能となる。ブログの解析は、数千万人の生活をリアルタイムで観測する電子顕微鏡の役割を担うことが期待され、消費者の声を拾うために企業側でも利活用が盛んに行われている。
1日ごとに、たくさんの人によって新規に書き込まれたブログの記事を寄せ集め、書き込まれた文章を単語に分解し、それぞれの単語の出現頻度を時系列にする。その時系列変化を解析することで、人々の関心の移り変わりを特徴づける単語を自動的に抽出する研究も盛んに行われている。たとえば、「KY (空気読めない)」という言葉は、女子高生などの間で流行していた造語であったが、2007年以降、急激にメディアなどで使われはじめ、指数関数(tを時間、aを定数としたとき、y=a^tの形の関数)的に使用頻度が増加した。2008年にピーク期を迎え、その後、ゆっくりと減衰し、日常的な日本語の単語として定着している様子が観測できる。人気がある芸人さんなどの話題や、流行しているスイーツなども、KY と類似した関数でブームを迎える。まさに社会の中でどのようにブームが形成されていくのか、その関数形が観測できる。
ブログの中の単語の出現頻度の時系列は、その特徴から次の4つに大雑把に分類することができる。
1 非流行語——流行で使われている言葉でなく、出現頻度は一定値のまわりでランダムに時間的にゆらぐ変動(「しかし」「ともかく」など)
2 流行語——時間とともに指数関数的に数年単位で増加し、ピークを迎えて、指数関数で減少する変動(「KY 」、「パンケーキ」、映画タイトルなど)
3 ニュース語——突然、不連続的に劇的に増加し、その後、べき乗の関数(y=1/t^aの形の関数)で減少する変動(「津波」、「マイケル・ジャクソン」など)
4 イベント日語——特定のイベント日付に向かってべき乗で増加し、その後、べき乗で減少する変動(「クリスマス」、「こどもの日」など)
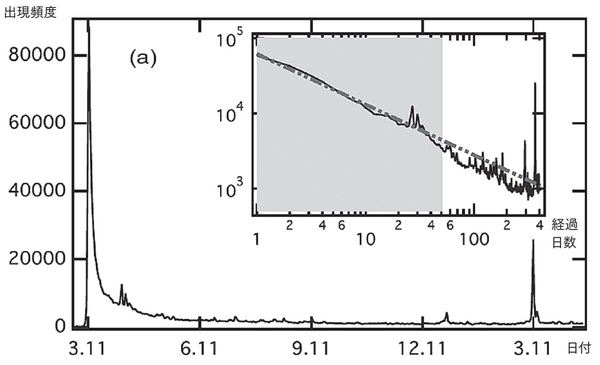
この中で3の「ニュース語」の典型的な事例として、図1に、「津波」という単語の出現頻度の時系列を紹介する。2011年3月11日、東日本大震災の日よりも前には、津波という単語は日常語の一つで、少ないが安定した数でブログに書き込まれていた。震災の当日、この単語の出現数は何万倍にも増加し、時間とともにゆっくりと減少していった。グラフを両対数でプロットするとほぼ直線的に書き込み数が減少しており、べき関数(y=1/t^aの形の関数)で近似することができる。この関数形が持続するものと仮定すると、津波という言葉の出現数が以前の日常語のレベルになるまでに、およそ25年かかるという推定ができる。企業不祥事などのニュースも、一気に話題になり、同様の関数に従うことが知られている。
4の「イベント日語」の典型は、たとえば、2月14日の「バレンタインデー」のようにイベントの日程が決まっているような単語で、その日に向かって期待がどんどん高まり、急激に口コミ数が増加する。しかし、イベントが終わると、急に関心がうすれ、時間的に急速に減衰するような振る舞いを示す。この関数形は、ちょうどその当日に発散するような、べき関数で近似できることが多いことがわかっている。このような特性を利用すると、イベント当日までにどれくらいの書き込み数があるかを、ある程度予測することが可能となる。通常で観測できるブログにおける単語の出現頻度の時系列では、1から4までの振る舞いの融合で、複雑な振る舞いをすることが知られている。
最近、そのような時系列変化を、簡単な規則に従いつつランダムに動くたくさんの人間の行動のモデルを構築し、シミュレーション実験を行うことで理解できるようになってきた。そのようなモデルを用いると、どのような関数でブームが進行し、イベントなどを開催する効果がどのようにあるのかなどを、シミュレーション実験であらかじめ定量的に予測できるようになる。
このようなシミュレーションによる研究から、2の指数関数で口コミ頻度が増減するブームは、直近の期間での増加分や減少分に比例して、新たにその言葉が書き込まれるようになるというメカニズムが背後にあることがわかる。つまり、どのくらいその言葉がソーシャルメディアなどに出現するのかに敏感に反応して、個々のブロガーが新たにその言葉を用いる確率が変化するのだ。ブームの背景のメカニズムは、たくさんの人間が集まったときの集団行動の特質として、金融市場の価格変化などいろいろな現象との類似性があり、ビッグデータが利用可能な時代の新たな社会科学として関心が持たれている。
")

